行列積の計算時間のOpenMPによる高速化 #
概要 #
OpenMP とは,並列計算機環境において,共有メモリ・マルチスレッド型の並列アプリケーションソフトウェア開発をサポートするために標準化されたAPIです.
gcc コンパイラは OpenMP に対応しているため,ソースコード内に既定のキーワードを書けば,OpenMP による並列処理ができます.
本ページでは,前ページ の結果に対し,OpenMP を用いることで,行列積演算の実行時間が短縮できることを確認します.
実験用に使ったプログラムは以下に配置しています.
OpenMP の利用 #
生の2次元配列で行列を表現する方式 (mdim_raw_array) は,以下の実装としています.
for (unsigned int i = 0; i < const_val::kSize; i++) {
for (unsigned int j = 0; j < const_val::kSize; j++) {
double& cij = c_[i][j];
for (unsigned int k = 0; k < const_val::kSize; k++) {
cij += a_[i][k] * b_[k][j];
}
}
}
OpenMP を利用する場合,以下のようにします.
unsigned int j = 0;
unsigned int k = 0;
double cij = 0.0;
#pragma omp parallel for private(j, k, cij)
for (unsigned int i = 0; i < const_val::kSize; i++) {
for (j = 0; j < const_val::kSize; j++) {
cij = 0.0;
for (k = 0; k < const_val::kSize; k++) {
cij += a_[i][k] * b_[k][j];
}
c_[i][j] = cij;
}
}
OpenMP に関する補足は以下のとおりです.
#pragma omp parallel forは#pragma omp parallelと#pragma omp forをあわせた意味です.- この場合,ループ変数
iによるループが並列処理されますが,その内部で使われる変数は,各並列処理単位ごとのもので,共有させてはいけません.そこで,private(j, k, cij)キーワードでそうなるように宣言しています. - ビルド時に
-fopenmp -lgompのフラグを追加します.-fopenmpフラグがなければ,#pragma omp ...の文は無視されるので,OpenMP を使う場合,使わない場合で同じコードが利用できます.ただし,本実験用の実装では,計測対象を明確に分離するため,別ファイルで管理します.-lgompはライブラリへのリンクの指定です. - 実行時に
export OMP_NUM_THREADS=16として,環境変数OMP_NUM_THREADSにスレッド数を指定します.ここでは,16スレッドとします.
数値実験 #
前ページ において,処理速度だけでみると以下が有用であろうと結論づけました.
- コンパイル時に行列サイズがわかっている場合:行列を2次元の生配列で表現する
- コンパイル時に行列サイズがわかっていない場合:
std::vectorの1次元配列で表現して転置をとる
そこで,これら方法 (mdim_raw_array, sdim_vector_trans) と,これらに OpenMP を適用した方法 (mdim_raw_array_openmp, sdim_vector_trans_openmp) の合計4種類の方法について,前ページと同様の方針で,実行時間を比較します.条件のみ再掲します.
実行時間は,以下の手順で計測します.
- 行列積の演算を続けて10回行い,その開始時刻と終了時刻の差を10で割る.
- その操作を100回行い,その平均値を計測結果として採用する.
実行環境は以下のとおりです.
- CPU: 13th Gen Intel(R) Core(TM) i7-1360P (16コア)
- メモリ: 16.0GiB
- OS: Linux (Ubuntu 22.04.3 LTS)
- コンパイラ: g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
実行結果は以下のとおりです.
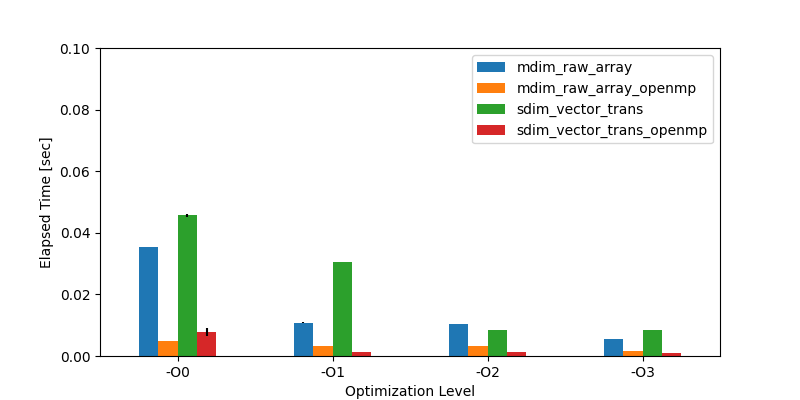
Figure 1. 実行結果
| Elapsed Time [sec] | -O0 | -O1 | -O2 | -O3 |
|---|---|---|---|---|
| mdim_raw_array | 0.035509 | 0.010723 | 0.010267 | 0.005574 |
| mdim_raw_array_openmp | 0.004792 | 0.003170 | 0.003162 | 0.001575 |
| sdim_vector_trans | 0.045625 | 0.030493 | 0.008451 | 0.008480 |
| sdim_vector_trans_openmp | 0.007657 | 0.001174 | 0.001212 | 0.001077 |
最適化レベル3 (-O3) の結果をみると,OpenMP を適用した結果,sdim_vector_trans はほぼ1ミリ秒(0.001秒)まで実行時間が短縮されたことがわかります.
OpenMP を使わないと8ミリ秒なので,約1/8ほど短縮できていることがわかります.
したがって,OpenMP による実行時間の短縮効果が観測できました.
まとめ #
本ページでは,前ページ の結果に対し,OpenMP を用いることで,行列積演算の実行時間が短縮できることを確認しました.
その結果,std::vector の1次元配列で表現して転置をとる方式 (sdim_vector_trans) に OpenMP を適用すると,そうしない場合の約1/8の実行時間となり,ほぼ1ミリ秒(0.001秒)まで実行時間が短縮されたことがわかりました.
したがって,OpenMP による実行時間の短縮効果が観測できたといえます.